The explosion in the amounts and variety of information
has made the knowledge about its existence, location, and the means
of retrieval very confusing. The information explosion has further
accelerated with the acceptance of the World Wide Web
[ber92],
causing a universal rush to create Web pages and use them to provide
on-line access to the vast legacy of existing heterogeneous information.
Such information ranges from documents in a variety of proprietary
representation formats to engineering and financial databases, and
is often accessible only through specialized vendor tools and locally
developed applications. Moreover, rapidly increasing sophistication in
presenting information on the Web is already forcing us to treat
ftp and gopher information sources, and even early
HTML pages as parts of the same legacy.
There have been numerous attempts to provide partial remedies for data
heterogeneity by implementing a variety of ever-changing
filters for format conversions. The filters are used to generate
HTML documents either dynamically, using the
Common Gateway Interface
(CGI)
mechanism, or off-line. The off-line approach
requires substantial human and computing resources for the initial conversion
and maintenance of information. Maintaining the repositories presents the
additional dilemma of either creating new and updating existing information
in HTML, or
continuously managing evolving data in multiple formats.
The dynamic approach helps to postpone the conversion until the information
is requested and eliminates problems with the initial processing and
maintenance of information. However, the access-time conversion may not be
appropriate for some rich document formats (framemaker, etc.) for the
following reasons:
There have been a number of attempts to build logical models of
distributed heterogeneous information and use these models to support
advanced Web presentation.
The Multimedia-Oriented Repository Environment
(MORE) [eic94]
was designed as a set of CGI programs
that operate in conjunction with a stock
httpd server to provide
access to a relational database containing meta-information, which
specifies how to retrieve physical data. The meta-information is
entered into the database off-line by the human librarians.
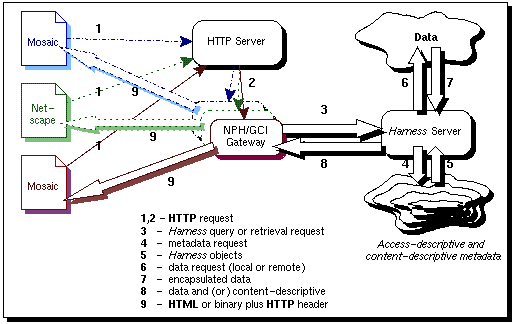
3.0 The InfoHarness System
The main components of the current
InfoHarness implementation
include (Figure 1):
- The
InfoHarness server, which uses
metadata to traverse, search, and retrieve the original information.
- The
CGI gateway, which is used to
pass requests from HTTP clients to
the InfoHarness server
(via an HTTP server) and responses
back to the clients.
- The metadata generator, which supports the off-line generation of
the
InfoHarness metadata entities
representing the desired logical structure and organization of the
original information. This metadata is used by the
InfoHarness server to support
dynamic search and presentation of raw data.
At access-time, the Web clients issue query, traversal, or retrieval requests
that are passed on to the gateway, which performs the following operations:
- Parses the request, and reads input information when the request is
associated with an
HTML form.
- Establishes a socket connection with the
InfoHarness server, generates
and sends out a request, and waits for a response.
- Parses the response, converts it to a combination of
HTML forms and hyperlinks, adds
an HTTP header, and passes the
transformed response to an HTTP browser.
The InfoHarness architecture is open,
modular, extensible and scalable.
The InfoHarness server implements the
abstract class presentation hierarchy that does not have to be modified
to support a new data type, or a new
indexing technology [shk95-1]. The methods associated
with abstract classes are general enough because they are data-driven and
can invoke independent programs.
The definitions of terminal classes are also data-driven and are not part of
the implementation, which makes the system capable of supporting arbitrary
information access and management tools (e.g., browsers, indexing
technologies, access methods).
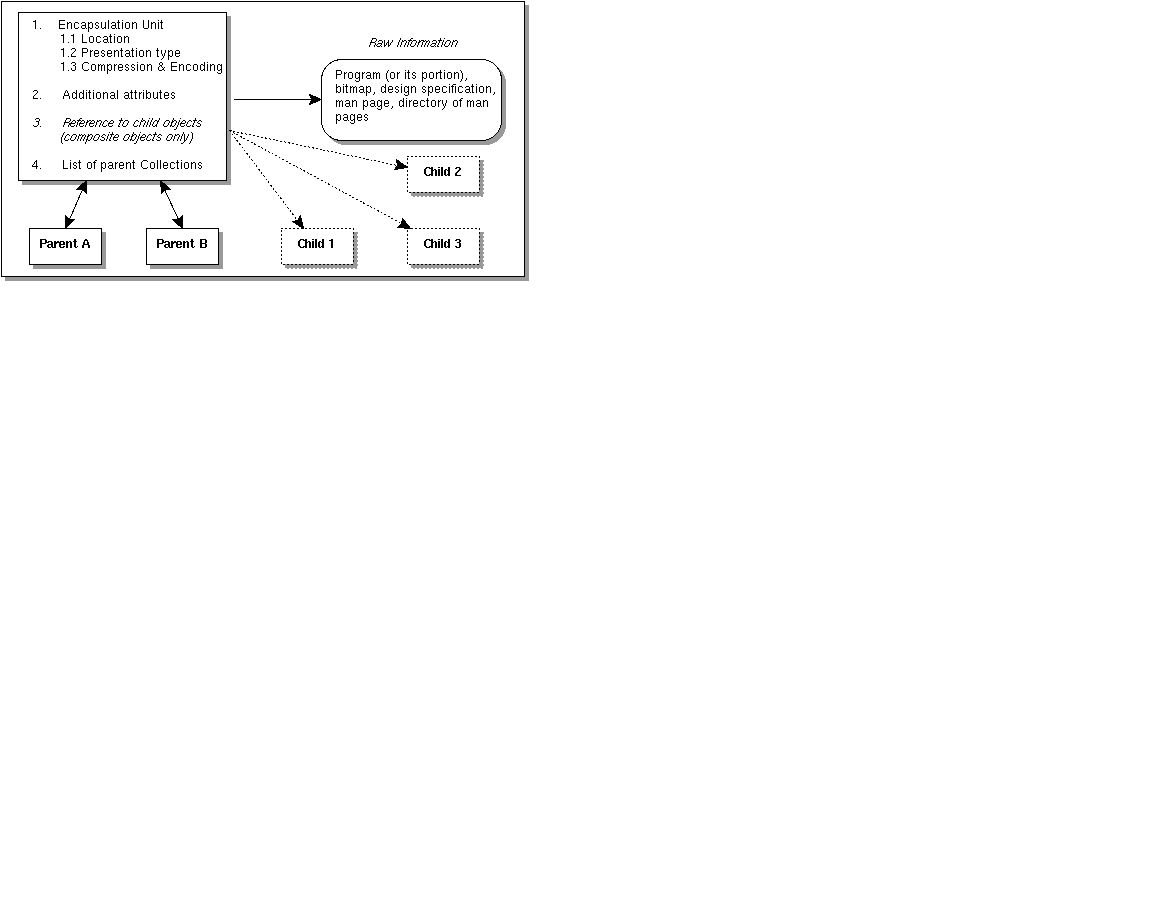
Figure 2. Simple and Composite Objects.



 hdl://cnri.dlib/april96-shklar
hdl://cnri.dlib/april96-shklar
{kind=link}
{kind=link}