| ||
D-Lib Magazine | |
| William Birmingham,
<wpb@eecs.umich.edu> |
![]()
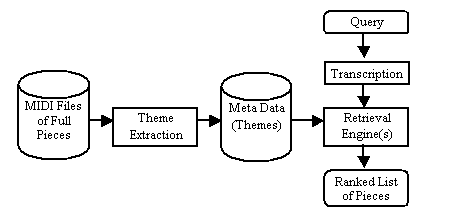
IntroductionMusic websites are ubiquitous, and music downloads, such as MP3, are a major source of Web traffic. As the amount of musical content increases and the Web becomes an important mechanism for distributing music, we expect to see a rising demand for music search services. Many currently available music search engines rely on file names, song title, composer or performer as the indexing and retrieval mechanism. These systems do not make use of the musical content. We believe that a more natural, effective, and usable music-information retrieval (MIR) system should have audio input, where the user can query with musical content. We are developing a system called MusArt for audio-input MIR [1, 2]. With MusArt, as with other audio-input MIR systems [3-5] [6-9], a user sings or plays a theme, hook, or riff from the desired piece of music. The system transcribes the query and searches for related themes in a database, returning the most similar themes, given some measure of similarity. We call this "retrieval by query." In this paper, we describe the architecture of MusArt (shown in Figure 1). An important element of MusArt is metadata creation: we believe that it is essential to automatically abstract important musical elements, particularly themes. Theme extraction is performed by a subsystem called MME, which we describe later in this paper [10]. Another important element of MusArt is its support for a variety of search engines, as we believe that MIR is too complex for a single approach to work for all queries. Currently, MusArt supports a dynamic time-warping search engine that has high recall [11], and a complementary stochastic search engine that searches over themes, emphasizing speed and relevancy. The stochastic search engine is discussed in this paper.
Theme ExtractionWe expect that the primary input mode for users will be humming or singing of some melody from the piece for which they are searching. To simplify the retrieval process, we search over an automatically generated database of melodies: the major themes or hooks of a song. Because themes are much smaller and less redundant than the full piece, we simultaneously get faster retrieval (by searching a smaller space) and get increased relevancy. Relevancy is increased as only crucial elements -- themes, melodies or hooks -- are searched, thereby reducing the chance that less important, but frequently occurring, elements are assigned undue relevancy. Successful searching, therefore, depends on the "hook" or theme of a piece of music being in our database. Extracting the major themes from a piece of music is very difficult. "Thematic extraction," as we term it, has interested musicians for years; music librarians and music theorists create thematic indices to catalog the works of a composer or performer. Moreover, musicians often use thematic indices (e.g., Barlow's A Dictionary of Musical Themes [12]) when searching for pieces (e.g., a musician may remember the major theme, and then use the index to find the name or composer of that work). These indices are constructed from themes that are manually identified by trained music theorists. Construction of these indices is time consuming and requires specialized expertise. Theme extraction using computers has also proven very difficult. The best known methods require some "hand tweaking" [13] to at least provide clues about what a theme may be or to generate thematic listings based solely on repetition and string length [14]. Figure 2 illustrates these problems. Here, the "1st theme" is played by the viola (the third highest voice in the piece) and begins in the third measure. Note the prevalence of the "background material" as compared with the "1st theme". Finding and ignoring the "background material" is what makes theme extraction difficult. There are many aspects to music, such as melody, structure and harmony, each of which may affect what we perceive as major thematic material. Extracting themes is a difficult problem for many reasons. Among these are the following:
Our theme extractor, MME, exploits redundancy that is found in music: composers will repeat important thematic material. Thus, by breaking a piece up into note sequences and seeing how often sequences repeat, we identify the themes. Breaking up involves examining all note sequence lengths of two to some constant. Moreover, because of the problems listed earlier, we must examine the entire piece and all voices. This leads to very large numbers of sequences (roughly 7000 sequences on average, after filtering), thus we must use a very efficient algorithm to compare these sequences. Once repeating sequences have been identified, we must further characterize them with respect to various perceptually important features in order to evaluate if the sequence is a theme. This is essentially a filtering step, where we attempt to find and remove "background material". In this step, we score the patterns MME extracts along nine features. The scores are then used to rank the patterns, with better scoring patterns considered as themes. One important feature is intervallic variety. We have found that sequences of repetitive, simple pitch-interval patterns occur frequently. For instance, in the Dvorak example (see Figure 2) the melody is contained in the second voice from the bottom, but highly consistent, redundant figurations exist in the upper two voices. Intervallic variety provides a means of distinguishing these two types of line, and tends to favor important thematic material since that material is often more varied in terms of contour. Learning how best to weight these features is an important part of our work. For example, we have found that the "rhythmic consistency" of a pattern is a stronger indication of thematic importance than is the register in which the pattern occurs (a counterintuitive finding). We implement hill-climbing techniques to learn weights across features. The resulting evaluation function then rates the sequences. Across a corpus of 60 works, drawn from the Baroque, classical, romantic and contemporary periods, MME extracts sections identified by Barlow as "1st themes" over 98.7% of the time. The extractions correspond to, on average, less than 3% of the content of the original work. Retrieval EngineDealing with errorsAny MIR system must deal with errors, and these errors are significant. We have found errors fall into the following categories:
Because errors are so common (all queries contain some errors), the design of the retrieval error revolves around ameliorating the effects of error. As the error sources are non-deterministic (we cannot accurately predict what error a given user will make on a given piece of music), we have chosen to use a stochastic representation of music in our system. In particular, we use hidden Markov models (HMM) to represent both queries and themes. Other researchers have used imprecise string matching to deal with errors, where the query and the target (either a theme or a full piece) are treated as strings with "noise". We believe that an HMM approach is more flexible than noisy strings, as we can explicitly model different error processes in the most suitable way. For a description of the HMM approach, please see Appendix 1. Finding the best target for a querySince we encode the themes in our database as HMMs and the query is treated as an observation sequence, we are interested in finding the model that is most likely to generate the observation sequence. This can be done using the Forward algorithm as described in Appendix 2. Experimental ResultsAs an initial test of the ideas in this paper, we constructed a database of pieces represented as hidden Markov models and generated a set of queries, sung by the authors. Themes in the database were ranked for similarity to each query and the ranked results were returned. Target corpus constructionWe collected a corpus of 277 pieces of music encoded as MIDI from public domain sites on the web. The corpus contained a wide variety of genres, including classical, Broadway show tunes, jazz and popular music from the past 40 years. Major themes for each piece were extracted by MME, yielding 2653 themes. An HMM was then automatically generated for each theme and placed in the database. Each theme was then indexed by the piece from which it was derived. Query corpus constructionEach singer was asked to sing three well-known pieces from the target corpus: America the Beautiful, Queen's Another One Bites the Dust, and The Beatles' Here Comes the Sun. Each singer was asked to sing any portion of the melody he considered significant, and the resulting query was recorded. Each singer was then asked to sing an additional three songs from the list of 277 pieces in the target corpus. The resulting query corpus contained six queries by each of four singers, for a total of 24 queries representing 15 different pieces. For each query, the full database of 2653 themes was scored using the Forward algorithm. Each of the 277 pieces in the target corpus was represented in the database by a set of roughly nine automatically generated themes. Pieces were ranked in order by the score of their highest-ranking theme. Table 1 shows that for 41.7% of the queries, the correct piece (i.e., the piece the singer was asked to sing) was ranked first and for 58% of queries the correct answer was in the top five. The median rank of the correct answer was 4th.
A query was defined as a success when the correct piece was returned as one of the top five matches. Study of the ten cases where correct title receive a score of sixth or worse revealed three main sources of system error: pitch tracker error (five cases), database coverage (one case), and ranking error (three cases). One query failed due to poor recollection of the theme by the person singing the query. SummaryWe have described a system for retrieving pieces of music from a database on basis of a sung query. The database is constructed automatically from a set of MIDI files, with no need for human intervention. Pieces in the database are represented as hidden Markov models (HMMs) whose states are note transitions. Queries are treated as observation sequences and pieces are ranked for relevance by the Forward algorithm. The use of note transitions as states and the Hidden Markov approach make for a system that is relatively robust in the face of key and tempo change. The use of observation probability distributions for hidden states deals with systematic error in query transcription. Hidden Markov models are an excellent tool for modeling music queries. The results of our experiments with this "first-step" implementation indicate both the promise of these techniques and the need for further refinement. Refinements to the hidden model topology and of the observation model will allow us to model a broader range of query behavior, and improve the performance of the system. AcknowledgementsRoger Dannenberg provided many helpful insights on this work. We gratefully acknowledge the support of the National Science Foundation under grant IIS-0085945, and the University of Michigan College of Engineering seed grant to the MusEn project. The opinions in this paper are solely those of the authors and do not necessarily reflect the opinions of the funding agencies. Appendix 1: The Hidden Markov ModelAppendix 2: Finding the Best Target Using a Query Forward AlgorithmReferences1. Birmingham, W.P., et al., "MUSART: Music Retrieval Via Aural Queries." Proceedings of ISMIR 2001. Bloomington, IN, 2001. 2. MusArt/MusEn Research Page. <http://musen.engin.umich.edu/"> 3. Kornstadt, A., "Themefinder: A Web-based Melodic Search Tool," Melodic Similarity Concepts, Procedures, and Applications, W. Hewlett and E. Selfridge-Field, Editors. Cambridge: MIT Press, 1998. 4. McNab, R.J., et al., "Towards the digital music library: tune retrieval from acoustic input." Digital Libraries. ACM, 1996. 5. McNab, R.J., et al., "The New Zealand Digital Library MELody inDEX." D-Lib Magazine. May 1997. 6. Tseng, Y.H., "Content-based retrieval for music collections." SIGIR. ACM, 1999. 7. Rolland, P.Y., G. Raskinis, and J.G. Ganascia, "Musical content-based retrieval: an overview of the Melodiscov approach and system." Multimedia Orlando, FL: ACM, 1999. 8. Blum, T., et al., "Audio databases with content-based retrieval." Intelligent multimedia information retrieval, M.T. Mayberry, Editor. Menlo Park: AAAI Press, 1997. 9. Clausen, M., et al., "Proms: A web-based tool for searching in polyphonic music." Proc. of the International Symposium on Music Information Retrieval. 2000. 10. Meek, C. and W. Birmingham, "Thematic Extractor." International Symposium on Music Information Retrieval. Bloomington, IN, 2001. 11. Mazzoni, D. and R.B. Dannenberg, "Melody Matching Directly from Audio." ISMIR. 2001. 12. Barlow, H., A dictionary of musical themes. New York: Crown Publishers, 1975. 13. Cope, D., Experiments in musical intelligence. The computer music and digital audio series. Vol. 12., Madison, Wisconsin: A-R Editions, 1996. 14. Alexandra and Uitdenbogerd, "Manipulation of music for melody matching." ACM Multimedia Electronic Proceedings. 1998. 15. R. Durbin, S.E., A. Krogh, G. Mitchison, Biological Sequence Analysis: Probabilistic models of proteins and nucleic acids. Cambridge, UK: Cambridge University Press, 1998. Copyright 2002 William Birmingham, Bryan Pardo, Colin Meek, and Jonah Shifrin | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Top | Contents | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| D-Lib Magazine Access Terms and Conditions DOI: 10.1045/february2002-birmingham
|