The Informedia Digital Video Library project is a research initiative at Carnegie Mellon University, funded by the NSF, DARPA, NASA and others, that studies how multimedia digital libraries can be established and used. Informedia's digital video library is populated by automatically encoding, segmenting, and indexing data. Research in the areas of speech recognition, image understanding, and natural language processing supports the automatic preparation of diverse media for full-content and knowledge based search and retrieval.
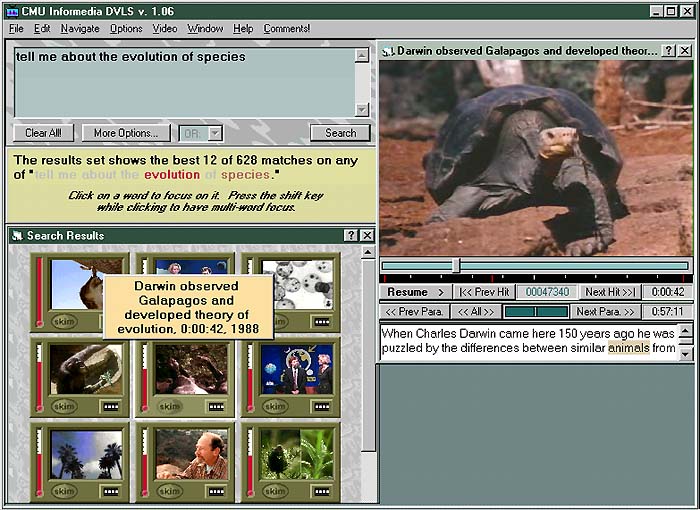
The following image is an example of how these components are combined in the Informedia user interface:
Currently, the Informedia collection contains approximately 1.5 terabytes of data, comprising 2,400 hours of video encoded in the MPEG 1 format. The content of this corpus includes approximately 2,000 hours of CNN news broadcasts beginning in 1996. The remaining content is derived from PBS broadcast documentaries produced by WQED, Pittsburgh, and documentaries for distance education produced by the BBC for the British Open University. The subject matter of the majority of these documentaries is mathematics and science. Also available is a small corpus of public domain videos, typically derived from government agency sources.
All the data in Informedia, except for the public domain videos, is copyrighted and must be used for research purposes only, with re-distribution prohibited. Users of the testbed will need to sign an agreement with the copyright holder.
The extensive, automatically derived metadata created by Informedia is an important resource for digital library researchers. Metadata for the Informedia collection includes:
For general information about Informedia, see the web site: http://www.informedia.cs.cmu.edu/.
Researchers with serious interests in using the testbed, should contact: Scott Stevens, sms@cs.cmu.edu.