|
Search | Back Issues | Author Index | Title Index | Contents |
![]()
D-Lib Magazine
|
|
|
Dr. Michael Mönnich Marcus Spiering |
![]()
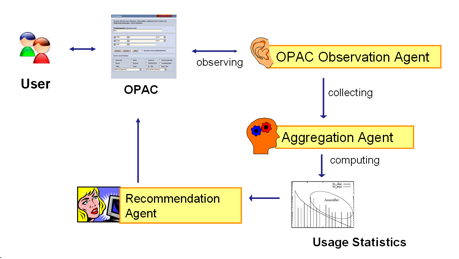
AbstractRecommender systems are useful tools for adding a reference component to a library catalog, and they help develop library catalogs that serve as customer-oriented portals, deploying Web 2.0 technology. Recommender systems are based on statistical models, and they can lead users from one record to similar literature held in the catalog. In this article we describe the recommender system BibTip, developed in Karlsruhe University, and we discuss its application in libraries. Recommender Systems in GeneralRecommender systems are flourishing on the Internet. One can hardly find a web shop that doesn't provide recommendations; the systems give customers hints about other interesting products and thereby boost sales. Probably, the example best known to librarians is the recommender system used by the online bookseller Amazon. Nearly any title there contains a link: "customers who bought this also bought ..." These referrals are generated by analysis and evaluation of the buying patterns of Amazon customers. Before the advent of the Internet, most recommendations came to us either from people we knew or from published reviews. Today's electronic recommender systems, on the other hand, function automatically and are generating recommendations without human intervention. Basically, electronic recommender systems function by statistically utilizing the data generated automatically by the user, from which the recommendations are then compiled. In this process the following variables are relevant: customers, products and shopping carts. To generate recommendations, the product selection in the shopping carts of customers is observed. The ability to identify which merchandise the customer actually purchased together at one shopping occasion is crucial for the quality of the recommender. Merchandise bought unintentionally together may not lead to reciprocal recommendations; merchandise purchased intentionally together are to be recommended. Recommender systems use statistical methods to differentiate between intentionally and unintentionally selected merchandise compilations. What determines the quality of the generated recommendations are the underlying statistical procedures used by the recommender systems. These vary according to the field in which they are applied. Their efficiency depends on the system's ability to separate the relevant from the irrelevant in the large number of clicks. Library services are well suited for the adoption of recommender systems, especially services that support the user in the search for literature in the catalog. From a librarian's point of view, a recommendation system can be seen as a form of catalog enrichment or as a substitute for traditional subject classification. The recommendation systems assist librarians in setting up and keeping up-to-date the library's holdings. From a more technical viewpoint, a recommendation system may be seen as a Web 2.0 application, since the user indirectly generates the data used by the system, and the integration into the catalog is being done by means of a mashup – two aspects of Web 2.0 applications. The Recommender System BibTipBetween 2002 and 2007, several projects funded by the German Research Foundation (Deutsche Forschungsgemeinschaft DFG)1 were carried out in Karlsruhe, all of them concerning the development of recommender systems for libraries. We called the first one the Karlsruher recommender system, but we changed its name to BibTip in 2007. Project partners in the development were Karlsruhe University Library2 and the Institute for Information Services and Electronic Markets of Prof. Dr. Andreas Geyer-Schulz.3 The Institute developed the algorithms and the scientific basis for the Karlsruhe recommender system, and the Karlsruhe University Library was responsible for the system's integration into the library catalog, the collection of statistical data and, most recently, the development and operation of BibTip as a service. The recommender system projects proved to be successful and were presented by the DFG at the Fall 2007 Task Meeting of the Coalition for Network Information CNI in Washington, DC, December 10 - 11.4 The BibTip recommendation system is based on the behavioral patterns of users interacting with a library catalog. This so called "implicit" recommendation service rests upon the observation of user patterns and the statistical evaluation of the usage data. All the data stored and processed are anonymous (identification numbers and session IDs). On a technical level the BibTip architecture may be seen as an agent architecture involving three software agents: the OPAC Observation Agent, the Aggregation Agent, and the Recommendation Agent. The OPAC Observation Agent observes the selection of titles within defined OPAC sessions. These data are transferred to the Aggregation Agent, which then does computations on the statistical material to arrive at a list of recommendations. Lastly, the Recommendation Agent presents the list of recommendations to the user.
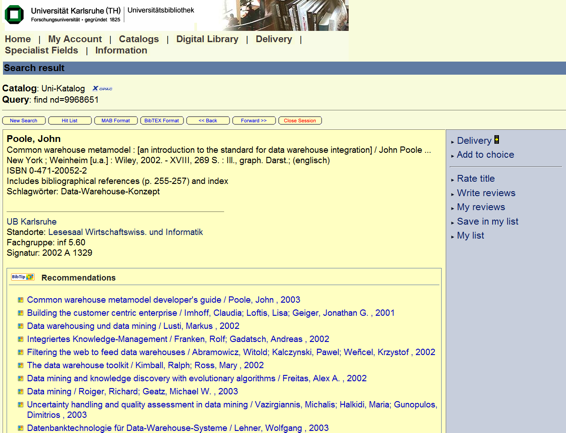
Whereas in the field of Internet commerce, user data are generated by purchasing transactions or clicks on links in web pages, in the case of BibTip, data are generated by aggregating the calls of full title displays during sessions in the online catalog. During the session, the user's views of full title displays in the catalog are counted. Based on the sessions, co-occurrences between pairs of titles are established if the two titles were viewed together in at least one session. These co-occurrences are counted and summarized in a co-occurrence matrix. In a further step, this matrix is evaluated in order to generate the recommendations. In this step the algorithms used play a crucial role. The algorithmic process upon which BibTip is based is particularly robust concerning disturbances, and the algorithm was developed especially for data in library catalogs. The basis for the Karlsruhe Recommender System is the Repeat-buying Theory developed by Andrew Ehrenberg, which describes regularities in a large number of consumer product markets on the basis of the analysis of shopping carts.5 The usage of the underlying theoretical distribution of independent purchase processes in a Poisson framework and applying the logarithmic series distribution-algorithm involved allow the setup of a recommender system that combines 100% automation, high precision and robustness against aberrations.6 (More detailed information about the mathematics behind BibTip can be found in the publication list of the project page "Recommender Systems for Meta Library Catalogs"7 at the Institute for Information Services and Electronic Markets.) After the calculation is done, recommendations generated by BibTip appear as hyperlinks in the full title display of the OPAC, and the links lead the user to content-related titles, as shown in Figure 2 below in Karlsruhe's catalog.8
Experience with BibTip in the libraryObviously, BibTip offers added value in the OPAC to library patrons. Many of the library's younger patrons are already accustomed to this type of service, because it is offered by web shops, Youtube and other Web 2.0 Services. The deployment of BibTip has several advantages for the library. One is that the recommendations never become outdated. Unlike the notations of a traditional classification scheme such as Dewey, Biptip recommendations are being constantly re-evaluated and are dynamically adjusted to the changing usage of literature by the user. If users at one point begin to use books in a different context than had been used before, this will be reflected in the lists provided by BibTip. As the number of recommendations represents a measure for the use of a title, a recommendation system may help in the development of the library's holdings. If a title has no recommendations, it would appear to be of little interest to the users. On the other hand, many recommendations for a particular title shows heavy usage of that title. Another point is that recommendations are completely media neutral. The lists can be created for any item in the catalog, whether they are books, videos, audios or journals. In addition, BibTip can be used in all databases containing bibliographic data, such as current contents or factual databases like PubMed. Last but not least, BibTip is very cost effective, since it entails a purely automated process. Once set up, BibTip needs no staff to run it. One might ask why BibTip uses the statistical analysis and evaluation of the catalog's usage for recommendations instead of using circulation data. This is because the latter approach would have several disadvantages. One is that reference books and all other literature excluded from lending would not be observed. Another point is that the accumulation of data is much higher using the catalog, since there are usually more catalog searches than books actually checked out. In addition, if the recommendations were calculated on circulation, then the recommendations would be influenced by the availability of the materials to be loaned. For example, books in high demand that are available only in one copy would be ranked lower than less interesting books that are available in more copies, because library users have the tendency to check out whatever is currently available to them. When dealing with recommender systems, the security and privacy of user data is an important aspect to consider. This matter is especially important in Germany where the legislation in this respect is strict. However, this is not a problem with BibTip, because BibTip collects and stores only data about anonymous OPAC sessions and title Ids or ISBNs. If BibTip were using circulation data though, these data would need to be anonymized to meet privacy and security considerations. BibTip, like other recommendation services, works better the larger the database is, since the statistical data are meaningful only if they are calculated on a sufficiently large number of transactions. Therefore, an observation period for the collecting and analyzing of data is necessary before the first recommendations can be displayed. This period is shorter the more data are stored, i.e., the more intensively the catalog is being used. The requirement for ample use, however, is bound to be fulfilled by most libraries, at least those at the university and college level. Besides this, the amount and usage of data, the number of titles called up during an OPAC-session, and the diversity of titles all influence the duration of the observation period. It should be noted that it is not necessary to have recommendations for all titles in the OPAC. The invocation of catalog data in ratio to the complete holdings usually follows a common Pareto-allocation, so that approximately 80% of the searches affect only 20% of the titles in the catalog. Therefore, it is sufficient to supply recommendation lists for this 20%. At Karlsruhe we now have approximately 200,000 recommendation lists in our library catalog. Since this catalog contains 1,000,000 titles altogether, a sufficient coverage of 80% has been achieved. Nevertheless, a correct prognosis of the length of the observation period is quite difficult. It is probably a reasonable assumption that it will take several months before enough statistical material has been gathered for the first valid recommendations. One way to accelerate the build-up of sufficient data to generate recommendations is to pool the statistical data of several libraries. This might be particularly feasible for libraries with a common interest in their choice of titles and similar clientele (and comparable user behavior), for example, public libraries. Using BibTip as a Web ServiceWe consider a recommender system to be an important feature of an attractive OPAC and see a high potential in BibTip to improve the quality of catalog service to the user. The results from a user survey conducted in Karlsruhe between the years 2005 to 2006 that asked the users to vote on the quality of the recommendation service on a scale of 1 (very poor) to 5 (very good) showed that most users found the recommender service to be very helpful; the average rating came to 4.21.9 We decided to continue the development of the recommendation service even after the DFG funding ended in 2007, and to offer BibTip to other libraries interested in providing their users with recommendations. Therefore, we redesigned the software in a way that would allow us to run BibTip as a web service, and also to make it more flexible and scalable. Subscribing to BibTip can be a convenient way for libraries to offer a recommender system to their users, as no local software has to be installed or maintained, and all the statistical data analysis, the procurement and the administration of the recommendation system takes place on the servers located in Karlsruhe. To maintain these servers and the staff involved, we charge a moderate annual fee for the use of BibTip. Part of the fee is also being used to ensure the further development the software. So far, a substantial number of libraries have already opted for BibTip, including the German National Library at Frankfurt/M., universities at Freiburg, Braunschweig, Berlin, University of the Federal Armed Forces Hamburg, and Stuttgart, the Baden State Library and several college libraries in Baden-Württemberg and Berlin. With this community of libraries using it, the development of BibTip has been put on a secure basis for the future. Technical AspectsThe requirements for the integration of BibTip are:
There are two forms of BibTip integration: the standard integration through the title-ID and a simplified version using ISBN. The simplified ISBN integration allows the integration with only two additional lines of static HTML code in the full title representation. In this context "static" means that these code lines are always the same in each full title representation. The standard integration through the title-ID requires the addition of three more lines to the HTML code of the full title presentation. These lines contain dynamic parts that change depending on the text displayed. Table 1 provides an overview of the two forms of integration. Table 1
ISBN IntegrationIn the case of ISBN integration one needs to modify the HTML code of the full title display at the following points:
Below is a sample HTML source code for the simplified representation ISBN Integration: <body> Content Full title <div style="display:none" id="bibtip_reclist"></div> Content Full title <script src="http://recommender.ubka.uni-karlsruhe.de/js/bibtip_xxx.js" type="text/javascript"></script> </body> BibTip Standard integrationIn the case of standard integration, the required extensions of an OPAC full title display are:
Below is an example of HTML source code for the BibTip Standard Integration: <body> Content Full title <div id="bibtip_isxn" style="display:none">3-8266-1762-2,978-3-8266-1762-1</div> <div id="bibtip_shorttitle" style="display:none">Ajax ge-packt / Seeboerger-Weichselbaum, Michael; 2007</div> <div id="bibtip_id" style="display:none">26214927</div> Content Full title <script src="http://recommender.ubka.uni-karlsruhe.de/js/bibtip_xxx.js" type="text/javascript"></script> Content Full title <div style="display:none" id="bibtip_reclist"></div> Content Volltitel </body> The operating mode of the integration of BibTip is described in further detail at the BibTip Homepage.10 Future developmentAs the number of libraries using BibTip increases, interesting options open for further development, among these are the opportunity to pool data from several libraries and generating cross-library recommendations. This could be of interest to libraries with similar user profiles such as public libraries or to college libraries with similar disciplinary or research emphases. In that way libraries with only small catalogs (or low catalog usage) might also provide recommendations to their users. Another area for future development of BibTip is the provision of advanced administrative tools that give IT departments in their local libraries the ability to customize the layout and the texts produced by the recommendation agent without interference from the staff at Karlsruhe. Further scientific research on BibTip may also include analyzing and decreasing the build-up time needed before valid recommendations can take place, or clustering groups of recommendations to create entry points to subject searches in the catalog. More Information about BibTip can be found at the website at <http://www.bibtip.org>, and those who wish to try out the BibTip recommender system may do so using the library catalog at Karlsruhe.Notes and References1. DFG - Deutsche Forschungsgemeinschaft, <http://www.dfg.de/>. (For the English language version of this web page, see <http://www.dfg.de/en/index.html>.) 2. Homepage of the University Library Karlsruhe, <http://www.ubka.uni-karlsruhe.de/index_engl.html>. 3. Information Services and Electronic Markets <http://www.em.uni-karlsruhe.de/index.php?language=en>. 4. CNI Fall 2007 Task Force Meeting, <http://www.cni.org/tfms/2007b.fall/>. 5. Ehrenberg, Andrew S.: Repeat-buying: theory and applications. Amsterdam: North-Holland Publ., 1972. 6. Andreas Geyer-Schulz, Andreas Neumann und Anke Thede: Others also use. In: Research and Advanced Technology for Digital Libraries. Berlin, Heidelberg: Springer, 2003 (Lecture Notes in Computer Science; 2769), pp.113 - 125. 7. Recommender Systems for Meta Library Catalogs, <http://www.em.uni-karlsruhe.de/research/projects/reckvk/index.php?language=en>. 8. University Library Karlsruhe Catalog, <http://www.ubka.uni-karlsruhe.de/katalog>. 9. Andreas Geyer-Schulz, Andreas Neumann und Anke Thede. An Architecture for Behavior-Based Library Recommender Systems. Information Technology and Libraries 22(4), pp.165 - 174 (2003). 10. BibTip flyer in English, <http://www.bibtip.org/bibtipFlyer_en.pdf>. Copyright © 2008 Michael Mönnich and Marcus Spiering |
||||||||||||||||
| |
||||||||||||||||
|
Top | Contents | ||||||||||||||||
| | ||||||||||||||||
|
D-Lib Magazine Access Terms and Conditions doi:10.1045/may2008-monnich
|