|
|
|
| P R I N T E R - F R I E N D L Y F O R M A T | Return to Article |
D-Lib Magazine
November/December 2010
Volume 16, Number 11/12
Federated Content Rights Management for Research and Academic Publications Using the Handle System
Guo Xiaofeng1
Institute of Scientific and Technology Information of China
guofx@wanfangdata.com.cn
Li Ying
Institute of Scientific and Technical Information of China
liying@istic.ac.cn
Sam X. Sun
Corporation for National Research Initiatives
ssun@cnri.reston.va.us
doi:10.1045/november2010-guo
Abstract
We report on a prototype project for a content rights registration and discovery service in China. It takes a federated approach to a content rights registration and discovery service framework that will be simple to operate and manage by individual publishers and content distributors, yet sharing a common service interface to ensure interoperability as well as open access to the general public.
Introduction
While digital publishing has had a strong presence in China for a number of years, there has been limited attention paid to content rights registration and discovery, especially in the research and academic community where most works represented in digital form are made available to the general public. While the issue could simply be addressed by establishing a centralized registration agency, the process for its establishment could be complicated and possibly so difficult as to be impossible. It would also mean extra cost for individual publishers and content providers who would have to pay for the registration of their content. Acceptance of such an approach appears unlikely, especially for small and medium sized publishers with very limited budgets.
This paper presents a federated approach for addressing this issue. The objective of our approach is to establish a federated content rights registration and discovery service framework that will be simple to operate and managed by individual publishers and content distributors, yet sharing a common service interface to ensure interoperability as well as open access to the general public.
Our approach consists of three major parts:
- Establish a standard global identifier service for content rights registration and resolution. Content rights registration from any individual publishers and content providers would be registered using the standard identifier service and would be resolvable and accessible by the general public.
- Establish a standard metadata structure to ensure interoperability in content rights description. The structure must be powerful and precise enough to describe all aspects of content rights, but also flexible and extensible to allow for future improvement.
- Establish a federated service framework in which individual publishers and content providers can operate and manage their own content rights registration without reliance on any third party operation. Standard web service interfaces among these services need to be established to ensure interoperability and provide service access to the general public.
Our approach results from a joint research project involving Wanfang Data Inc., ISTIC, Content Digital Inc., all in China, and Corporation for National Research Initiatives (CNRI) in the US. The goal of the joint research project was to investigate possible ways of establishing a standard global identifier service in China, and to identify any practical applications that would benefit from such a service. The project identified the Handle System, developed by CNRI, as the best candidate for the standard global identifier service in China, based on its federated service framework, the built-in data security and service integrity, the highly efficient and scalable service protocol, and the reliable service implementation.[1, 2, 3] The project also showed that a secure global identifier service could play an important role in addressing content rights registration and discovery, as well as its life-cycle management, under a federated service environment.
The Handle System, a key component of the Digital Object Architecture [4, 5], is a distributed information system designed to provide an efficient, extensible, and secure global identifier service for use on the Internet. The Handle System includes an open protocol, a namespace, and a robust implementation of the protocol. The protocol enables a distributed computer system to store identifiers (or handles) of digital resources and resolve those handles into the information necessary to locate, access, and otherwise make use of the resources. These associated values can be changed as needed to reflect the current state of the identified resource without changing the handle. This allows the name of the item to persist over changes of location and other current state information.[6] Each handle may have its own administrator(s); and administration can be done in a distributed environment. The Handle System supports secure handle resolution.
This paper provides a detailed description of our prototype implementation of the federated service framework for content rights registration and discovery. Our intention is to gather feedback from the community and to make the content rights registration and discovery service affordable to individual publishers and/or content providers, under a federated service framework that is both secure and interoperable across various implementations.
Rights Registration and Discovery Service
Our overall service architecture starts with each publisher hosting a local handle service as the core of their content rights registration service. Each organization will be allocated a unique handle prefix as the namespace for their handle service. The organization will register all of its content items under this handle service, each identified by a handle. Content rights as well as ownership information will be registered as handle attributes of the corresponding handle. The distributed nature of the Handle System allows each organization to operate and manage their handle service independently from any third party operation. It also ensures that handles registered by each organization are globally unique, and can be resolved by a user over the Internet.
Service Architecture
Figure 1 shows the overall architecture of our proposed framework. Publishers register their digital content in their own local handle service. Each handle record will hold metadata attributes that describe the content rights, including ownership information, of the identified content. A web service interface is added that enables access to the handle service to accept user inquiry from any browser interface, and to support for content rights exchange among different publishers and other content providers.
The Global Handle Registry, the root of the Handle System, enables the discovery of each and every local handle service. Given the handle of any digitally published content, the Global Handle Registry will direct the user to the responsible local handle service based on the handle prefix. The local handle service can then be queried for the rights information required by the user, and redirect the user to a web service interface where rights information can be rendered. For any registered local handle service, the Global Handle Registry also provides public-key information that can be used to authenticate the local handle service, and so ensure the service integrity.
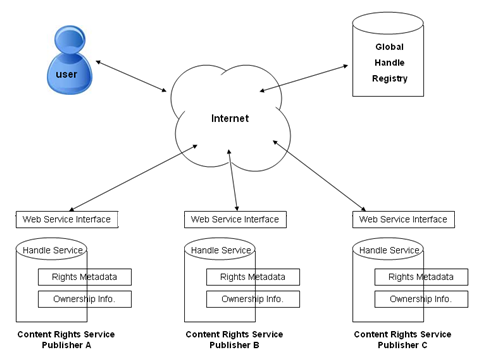
Fig. 1: Content Rights Registration and Discovery based on the Handle System.
Rights Metadata Description
The goal of our project is to encourage the discovery and circulation of research and academic publications in digital form. Associating rights and permissions with each article is key to reaching this goal. Figure 2 shows the basic structure of our metadata schema. As shown in Figure 2, our metadata schema consists of two major sections, the "copyright statement" section and the "rights" section. The "copyright statement" section is used to provide information related to copyright, including the author's name, date of publication, as well as information that helps identify the author. The "rights" section is used to describe various aspects of rights associated with the published content. This includes the Work, License, Jurisdiction, Permission, Requirement, and Prohibition attributes. The Work statement is intended to provide information on the research project being reported, whether it's funded or not, and the source of the funding. The License statement defines different levels of rights associated with the content. The Permission statement specifies whether the content can be used for public display, distribution, reproduction, aggregation, and other purposes. The Prohibition statement indicates whether or not the content can be applied to commercial use.
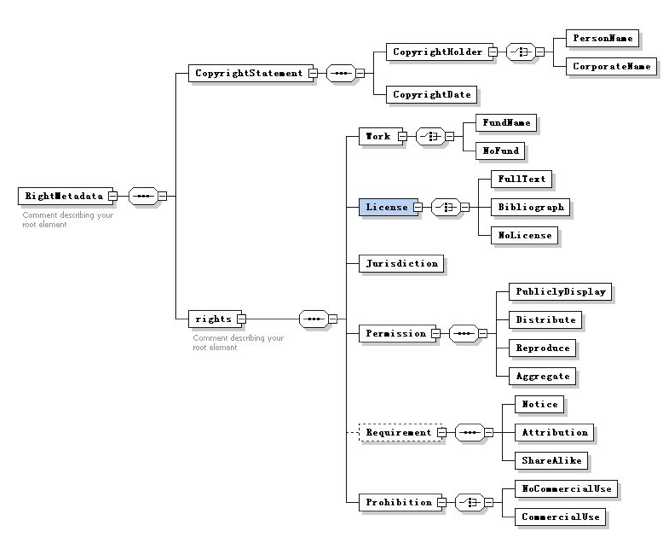
Fig. 2: Rights Metadata Schema in support of a license framework.
In our prototype development, each handle registered for the purposes of content rights is assigned a profile in the form of a specific attribute type: "10403.type/profile". The value of the profile attribute in our prototype is always "content right registration", which indicates that the handle is used for content rights registration. Any handle used for the content rights registration can be expected to have a handle attribute that has attribute type "10403.type/rights.metadata". The value of the attribute will be the metadata information encapsulated in XML format. Here "10403" is the top level handle prefix issued to ISTIC for the collaboration project. Handles for content rights registration typically contain a URL attribute that redirects to the web service interface of its content rights registration service. The web service interface will generate an appropriate display of the content rights based on the metadata attribute.
Each publisher hosting a content rights registration and discovery service will be allotted a unique handle prefix derived from "10403", so that handles registered from different publishers will not conflict with each other. When content ownership changes hands from one publisher to another, a new handle will be registered by the new publisher under its own local handle service, with a new set of attributes describing the rights information. The old handle will continue to exist, but will be designated as an alias handle that refers to the new handle.
Rights Discovery Process
Given the globally unique handle assigned to some published content, an Internet user can find the underlying content rights by sending an inquiry to a content rights registration service hosted by any publisher. The user may send the inquiry directly to the web service interface of a content rights registration service. In the case in which the handle (as well as the identified content) belongs to some other publisher, the content rights registration service will consult the Global Handle Registry to find out the responsible local handle service for that handle, and redirect the user to the correct responsible rights registration service.
In the case in which the user doesn't know of any content rights registration service, the user can always send the handle resolution request to the well-known web-to-handle proxy service by constructing a URL of the form hdl.handle.net followed by the handle. The resulting URL redirection from the proxy service will redirect the user to the responsible content rights registration service.
Figure 3 shows a typical use case scenario for the content rights discovery process. In figure 3, Adam goes to the website of his favorite content rights registration service, and enters the handle to check out what he can do with the associated content. The content rights registration service finds that the handle is managed by another party (i.e., it has a different handle prefix), and consults the Global Handle Registry to find the responsible local handle service. The user's query is then redirected to the responsible content rights registration service. The responsible content rights registration service will process the query, and return the content rights information to the user's browser.
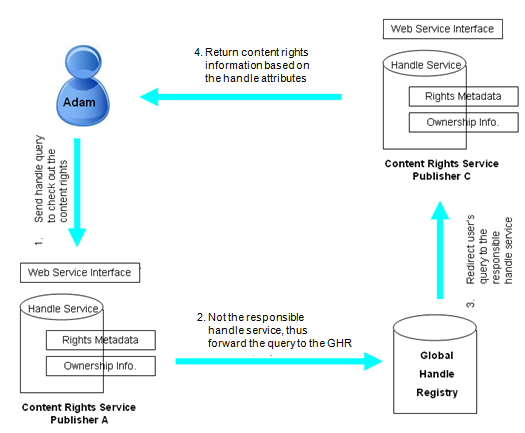
Fig. 3: Content rights discovery process.
Conclusion
Content rights registration and discovery are important services supporting digital publishing, and the use of appropriate mechanism for content dissemination. This paper shows a federated approach in which content rights registration and discovery can be hosted and managed by individual publishers and/or content providers, without reliance on any third party operation. The key to our approach is to leverage the security and distributed features of the Handle System technology with a standard set of web service interface and metadata definitions to support content rights registration and discovery.
Our next step is to apply our approach in other areas of content rights related applications, including copyright registration and patent registration in China. We are also investigating better ways to integrate content rights registration and discovery services with content dissemination channels for automated content delivery, as well as federated client authentication services for improved security.
Note
This article represents the views of the authors and not necessarily their respective organizations.
References
[1] Sam Sun, Larry Lannom, Brian Boesch, "Handle System Overview". Internet Engineering Task Force (IETF) Request for Comments (RFC), RFC 3650, November 2003, hdl:4263537/4069.
[2] Sam Sun, Sean Reilly, Larry Lannom, "Handle System Namespace and Service Definition". Internet Engineering Task Force (IETF) Request for Comments (RFC), RFC 3651, November, 2003, hdl:4263537/4068.
[3] Sam Sun, Sean Reilly, Larry Lannom, Jason Petrone, "Handle System Protocol (ver 2.1) Specification". Internet Engineering Task Force (IETF) Request for Comments (RFC), RFC 3652, November, 2003, hdl:4263537/4086.
[4] Robert E. Kahn and Robert Wilensky. "A Framework for Distributed Digital Object Services". International Journal on Digital Libraries, (2006) 6(2): 115-123. doi:10.1007/s00799-005-0128-x. (First published by the authors May 13, 1995, "A Framework for Distributed Digital Object Services", hdl:4263537/5001).
[5] Robert E. Kahn and Jay Allen Sears. "A Brief Overview of the Digital Object Architecture". October 2003, hdl:4263537/5022.
[6] The Handle System: http://www.handle.net/.
About the Authors
 |
Guo Xiaofeng is a Senior Engineer and Director of the Chinese DOI Operation Management Center at the Scientific and Technical Information of China (ISTIC). Her research interests are digital publishing based on DOI, and information services based on the Handle System. She and the research team from ISTIC, Wanfang Data Research, and CDI, have collaborated with CNRI since 2007, developing an open content rights registration prototype based on CNRI's Handle System. |
 |
Li Ying is a Senior Researcher at the Information Technology Support Center, Institute of Scientific and Technical Information of China (ISTIC). Her research interests are Web based information systems, knowledge-based systems, electronic publishing based on XML, and DRM based on handles. She graduated with Doctoral degree in information science, specifically information systems, from University of Tsukuba in 2006. |
 |
Sam X Sun is a Senior Research Scientist at Corporation for National Research Initiatives. He played a key role in the development of the Handle System protocol and service architecture, and has participated in standards activities in Internet security, digital rights management, and Grid computing. He is the lead author of the IETF RFCs that describe the Handle System interface specification. He has led a number of research collaborations that applied the Handle System technology to digital library development, healthcare informatics, and Internet identity management. |
|
|
|
| P R I N T E R - F R I E N D L Y F O R M A T | Return to Article |